I paid for Flickr for years. By my email it looks like I started somehere in 2007 or 2008 and continued to pay all the way into 2015 or so. It was a great product and the first of its kind for unlimited storage. Time now is hazy, but I think I decided to finally stop paying once I purchased my own NAS and Yahoo decided to up the free tier to one terabyte. "Why continue paying?", I thought.
Flickr announced on November 1st that they'd be changing (read: downgrading) Flickr free accounts to just a thousand photos.
Beginning January 8, 2019, Free accounts will be limited to 1,000 photos and videos. If you need unlimited storage, you’ll need to upgrade to Flickr Pro.
Flickr Pro isn't expensive, but I'm already paying for Google Photos storage. And it's a great product and only getting better. I need extra incentives to switch. Flickr still is a great professional platform for photos but they need to invest more in their mobile app, the online experience, and much more to be appealing. It was time to abandon ship.
Thankfully, Flickr has provided a way to download all your content but like other online services, they provide the bare minimum to do so. This ends up being a giant list of gigabyte sized zip files.
"Screw this", I thought, "I'll find a Flickr library to let me download everything where I want with image metadata included hopefully. For we live in the age of Github!"
flickrdump came so close to doing exactly what I wanted, yet fell so far as I realized that while it would quickly and happily download all my public photos, it couldn't access my private photos. Which most of my collection remain so. I attempted at quickly created a fork with the proper logic to grab private photos however it appears that you need to go through the annoying OAuth process to grant access to your account, to your own Flickr app to request private photos. This may truly not be the case but there wasn't any documentation that I could find pointing me in the right direction.
I suddenly realized that I was completely overthinking this problem. All the links to the zip files were present on the dashboard page.
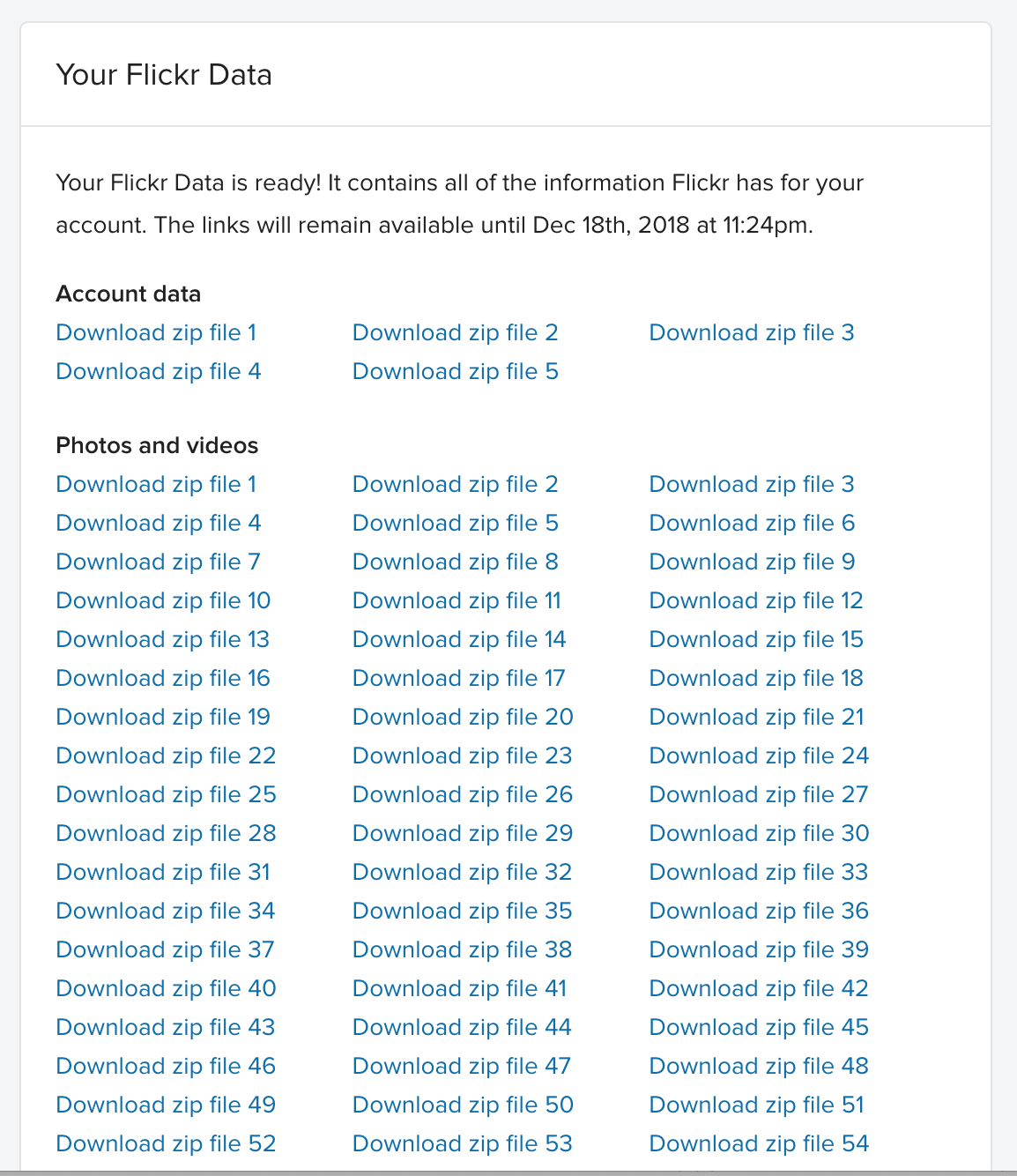
And, it turns out they don't require the login session cookie to be present in order to download them. So I devised the following:
First, print out all the links with a simple console command:
document.querySelectorAll('.photo-data-list, .account-data-list')
.forEach( item =>
item.querySelectorAll('a')
.forEach((e) => {
console.log(e.href)
}
))Copy and paste from this Github gist, don't trust some rando's domain
Then, I passed all the URLs into a urls.txt file.
Lastly, turn it up to 11 and download all the files with wget concurrently with parallel. parallel[0] is a great tool in the GNU toolkit and easily allows you to run commands in concurrent fashion. The command I used is as follows:
cat urls.txt | parallel wget -t 3 -nvIn short:
cat urls.txt |: pipe all the urls to parallelwget: does the downloading[1]-t 3: if a failure occurs, retry each url thrice-nv: 'no verbose',wgethas a nice progress bar by default but with multiple downloads happening at once, I only care about lines letting me know a file is completed
I stepped out for a few hours and was pleased to find that all the files had successfully downloaded. I could now let my NAS back them up to the cloud and sleep soundly until the next photo platform collapse || acquisition || shutdown event.
[0] - More on parallel - https://medium.com/@alonisser/parallel-straight-from-your-command-line-feb6db8b6cee, https://linux.die.net/man/1/parallel